Make Pixel Art in Seconds with Machine Learning
Pixelate any image with Akvelon’s new PixelArt filter
Make Pixel Art in Seconds with Machine Learning
Pixelate any image with Akvelon’s new PixelArt filter
Hello, readers! My name is Irina and I’m a data scientist at Akvelon. Recently, Akvelon added a new filter to DeepArt, a platform that transforms photos and videos into works of art using neural networks. This new filter is called PixelArt, and can pixelate your photos and videos using machine learning.
In this article, I will tell you about the machine learning components of this project.
Let’s dive into the pixel art universe!

First of all, let’s find out what Pixel Art is, how it is used in 2021, and why it should be considered art.
Historically, pixel art is one of the most popular aesthetics in video games. It strives to recreate the look and feel of old Nintendo and Arcade titles. In the ’90s, pixel art was the only option for most console games. Now, pixel art style is popular again!
Pixel art is a unique art style, an appreciation of big visible pixels that make up the founding elements of the complete image.
There are several reasons why pixel art is so popular these days:
- Aesthetics. Pixel art looks awesome! The beauty often lies within its simplicity, with fantastic arrangements of big colored pixel blocks. To achieve this effect, graphic artists set up limitations and rules so the images will be in line with the expected, retro result.


- Simplicity. Pixel art is easy to understand, but different from the usual style of images. Moreover, creating pixel art is relatively easy to learn.

- Memories. Pixel art brings back great, nostalgic feelings for gamers who grew up playing Nintendo, Super Nintendo, or Genesis.

Some pictures in the pixel style can be surprising, with their elaboration and idea. Usually, it takes a lot of time for the artist to create such pictures, since you need to keep in mind the limitations in resolution and color palettes. Therefore, the idea of creating AI that will automatically apply the pixel style to any photo or picture seemed very appealing!
General Pixel Art rules
Some might think that the pixel style is just poor quality images with oversized pixels, but I want to explain how this is just untrue. A certain color gamut is used, and also in each case, its own pixel size is used to make the image look more harmonious.
Thus, we can formulate the following features of the pixel style:
- A certain color scheme:It is considered good practice to use the minimum number of colors; ideally — the standard 16 colors available on the vast majority of video subsystems, even the earliest ones: in them, three bits encode signals R, G, B and the fourth bit encodes brightness.
- Make individual pixels clearly visible, but not necessarily in low-resolution images.

How to transform images
The task definition
Now that we have defined what a pixel art style is, we can move on to the practical side of this article. Our task is to create a model that will take a usual picture, photo, meme, whatever you want, and convert it to pixel art style.
Let’s give a simple example to better understand what exactly we have to do. Imagine that the first picture is a photo of your favorite pet and the second one is a painting by Van Gogh “Starry night”. So, what you want to get is a new image of your pet but in Van Gogh style.

In other words, you need to extract the content from your pet photo and extract the style from the second image. After that, you can generate a new image by combining the content from your photo with the style from the second image. Such tasks are called Image-to-image translation.
Image-to-image translation is a class of vision and graphics tasks where the goal is to learn the mapping between an input image and an output image.
If we use machine learning models or neural networks to solve Image-to-image translation tasks, then this approach is called “Neural Style Transfer”.
For example, when you want to transform horses into zebras, or pears into light bulbs using machine learning — you become a magician with the “Style Transfer” wand!
General concepts
Since we have to generate a new picture in a certain way, we will use GAN (Generative Adversarial Network). The GAN architecture consists of a generator model for outputting new plausible synthetic images, and a discriminator model that classifies images as real (from the dataset) or fake (generated). The discriminator model is updated directly, whereas the generator model is updated via the discriminator model. As such, the two models are trained simultaneously in an adversarial process where the generator seeks to better fool the discriminator and the discriminator seeks to better identify the counterfeit images.
Possible approaches
As you may already guess, there are several approaches to do what we want:
1.Pix2Pix model. The Pix2Pix model is a type of conditional GAN where the creation of the output image depends on the input, in this case, the original image. The original image and the target image are input to the discriminator, and it must determine if the target is a plausible transformation of the original image. In this situation, only a paired dataset is used i.e each image in an original style is related with exactly the same image but in a different style.
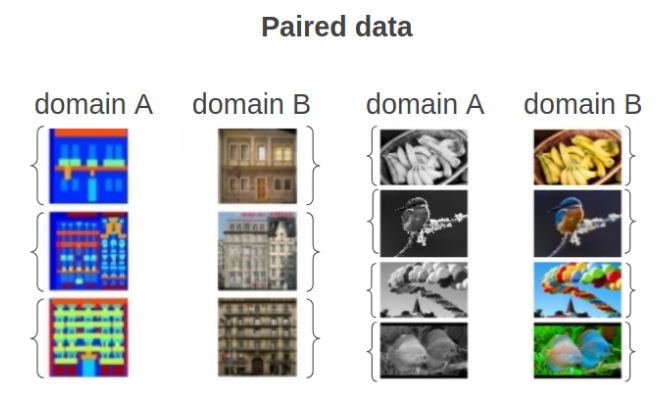
2.CycleGAN model. CycleGAN is a class of models that involve the automatic training of image-to-image translation models without paired examples. It transforms images from one domain to another and vise versa. The main difference between this approach and the Pix2Pix approach is that it isn’t necessary to use paired datasets. The models are trained in an unsupervised manner using a collection of images from the source and target domain that do not need to be related in any way.
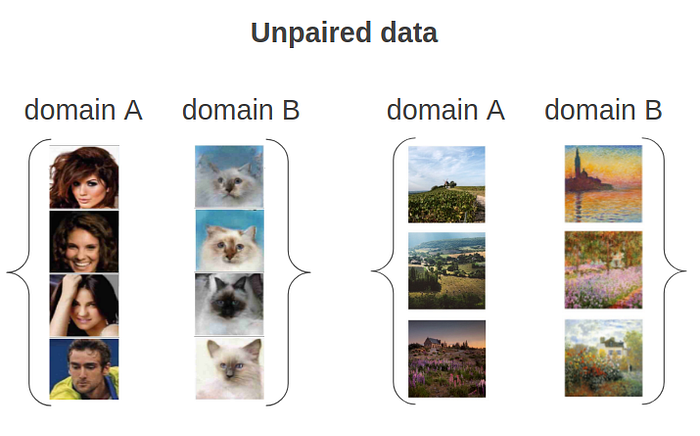
Collecting paired data is a difficult task because sometimes that data may not exist. This is why we decided to use the CycleGAN style transfer model.
About the data used
If you are still learning the ropes in data science, this information is just for you. But if you have some experience in data science, you already know that we have two ways to find data:
- Finding an existing dataset in open sources
- Collecting/parsing data for your task by yourself
Since the pixelization task is not trivial, while writing this article, suitable datasets did not exist. Therefore, we opted for the second way.
Looking ahead, I will say that we had several approaches to data selection.
In the first approach we experimented with custom datasets. We used ImageNet and MS COCO for domain A and parsed really magnificent images from //hello.eboy.com/eboy/ images for domain B.


But almost all of the model results were similar to these:

In the second approach this dataset was used. t contains many images of cartoon characters on a white background that are used for domain A and many images of Pixel Art cartoon characters on a white background that are used for domain B.


You will be absolutely right if you exclaim that “this dataset contains only cartoons, how could this model will work on images of real people or photographs!”
Keep calm and just see the results…


Yep, it works very well! But how can our model transform people into pixel art if we trained it only on cartoons?
I suppose it’s all about the generalization of the model. In a nutshell: during the learning process, when the model analyzes the data, it tries to identify patterns at different levels and remember them. And after being trained on a training set, a model can digest new data and make accurate predictions. Sometimes a model can find patterns that people cannot identify. Therefore, the choice and balance of the dataset is very important.
How we using CycleGAN
CycleGAN architecture in more detail
As you already know, GAN contains generator and discriminator. Above, we also said that CycleGAN transforms images from one domain to another and vice versa. For this reason, CycleGAN architecture contains two generators and two discriminators.
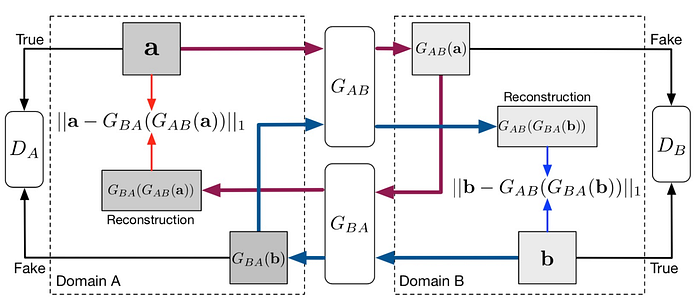
The first generator gets an image from domain A (any image in our case) and tries to generate an image from domain B (Pixel Art version of the image). The first discriminator gets generated images and real Pixel Art images from the training dataset and tries to distinguish generated images from real images. The generator and discriminator have opposite goals and opposite loss functions so they train simultaneously from one epoch to another.
The second generator and discriminator work in the opposite direction — the generator gets an image from domain B and tries to produce a “domain A” version of the input image. Discriminator tries to distinguish real “domain A” images from generated images.
The main interesting feature of CycleGAN is that it gets images from domain A, generates the “domain B” version, and then tries to reproduce the “domain A” version using the generated “domain B” version. Ideally, the initial image and after cycle pass using two generators should be the same, so CycleGAN also uses two more loss functions to compare images after cycle pass (A to B and B to A domains).
Implementation of the model
For implementation, we decided to use a transfer learning approach because it’s convenient, fast, and gives excellent learning results. We used PyTorch as a neural network framework, PyCharm IDE for a training model with GPU, and Jupiter and Google Colab notebooks for loading the checkpoint and showing results.
We were inspired as soon as we saw this repository that includes Pix2Pix, CycleGAN, CUT and FastCUT pretrained models for image style transformation. We took these models as a baseline and trained each of them on our custom cartoons dataset. Please explore repo to know more about the dataset type and different models because we will use this all below.
If you already have a checkpoint and do not want to train the model, you can skip to the Inference section.
If you want use these models with a custom dataset like us, just:
- Clone the repo and install requirements
2. Download a pretrained model (e.g. horse2zebra) with the following script:
bash ./scripts/download_cyclegan_model.sh <pretrained model name>3. Add your custom dataset in ./datasets directory
4. Move on to training the model
To view training results and loss plots, run python -m visdom.server and click the URL http://localhost:8097.
5. Test the model using the code below:
The test results will be saved to a html file here:
./results/<selected model name>/test_latest/index.html.
You can find more scripts at scripts directory.
Excellent! Now that you have a weights file, you can assume that you have already received good results.
And now we can move on to the inference part!
Inference
We should initialize our model architecture and load our weights file, which is also called the checkpoint. Despite the fact that our network architecture included generators and discriminators during training, during use we will take only the part that generates the image, that is, only the generator. You can see all model architectures in the repository, as they are too large to be included in the article. Note that the code below is in notebook format.

Let’s take a look at the code!
Firstly, we need to download the pretrained state dict of the CycleGAN Generator model for image pixelation. You can do it in any way that is convenient for you. In our case, the code looks like this:
Now we import the required libraries:
After that, we should define classes of the model. For this we will use the ResNet that stands for Residual Network. If you don’t know about residual neural network, you can explore it in more detail here. This is a really interesting approach that solves the vanishing gradient problem.
So back to our model, ResnetBlock is a part of ResnetGenerator that is used get Pixel Art versions of input images.
Now we can define the main model. ResnetGenerator is the neural network that gets any image and transforms it to Pixel Art image.
We need a function that returns a normalization layer based on the input string. This layer is used as a parameter for the constructor of the ResnetGenerator class.
Init model and load state dict
So, it’s time to create a ResnetGenerator object with 'instance' norm layers and initialize it with random weights.
And, of course, we need to check and define a device depending on CUDA availability.
We will load downloaded state dict and pass it to the network to change weights to pretrained values.
Cool, now we can move on to the last but not least part about applying the model and getting results.
Load and transform image
Let’s download the image that will be pixelated.

When working with images, we should always apply transformed operation images before passing them to the neural network. The set of transformations depends on your task, but in this case we will use a simple standard transform: turn the image into a torch tensor and normalize it.
Just load the downloaded image into Python code and apply the transformations.
Process image and save output to file
Finally we can pass the transformed image to the neural network.
After that, we need a last function that transforms the output of the ResnetGenerator neural network (that is PyTorch’s tensor) to a numpy array. This numpy array can be saved to disk as an image.
Just save and display pixelated image.

Looks great! But in this case we can only visually assess how the image matches the style of the pixel art. Of course, there can be disagreements about the final color solution or how well the final image matches the pixel art style, it’s up to you.
Results
So, in this tutorial, you should have learned:
- What is pixel art style
- Generic Pixel Art rules
- Image to image translation and style transfer task
- Existing approaches to solve style transfer
- What the choice of dataset effects
- How to define and train the CycleGAN model on custom dataset
Thank you very much for your attention!
About us
We at Akvelon Inc love cutting edge technologies in mobile development, blockchain, big data, machine learning, artificial intelligence, computer vision, and many others. This article is the result of one of many projects developed in our Office Strategy Labs where we’re testing new technologies and approaches before delivering them to our clients.
If you would like to work with our strong Akvelon team — please see our open positions.
Designed and implemented with love in Akvelon:
Team Lead — Artur Khanin
Technical Account Manager — Max Kostin
ML Engineers — Irina Nikolaeva, Rustem Saitgareev
